What is 3D Sound?
3D sound is an audio effect that creates the sensation for the listener of being in the space in which the sound originally came from. For example, a famous 3D sound recording is one where the listener feels as though they are in a barber shop (see video below), and can hear the barber move around them as he speaks, and almost feel the hair being cut from behind their head.
How it works
In order for a sound to give the listener the impression of a direction, the brain interprets the delays caused by the sound travelling different distances around the skull to each ear. When sound travels though the air, your ears on your head orient the sound, and then your brain knows where the sound is coming from.
Traditional surround-sound stereo recording relies on a physically removed speaker system which sound is again separated. Sound then travels to your ears from multiple sources, adding a delay offset to the signal, and then your brain interprets the direction of the sound. Unfortunately, this process does not preserve the delays for earphones, because your skull and ears are not inserting the directional delays into the signal.
Traditional surround-sound stereo recording relies on a physically removed speaker system which sound is again separated. Sound then travels to your ears from multiple sources, adding a delay offset to the signal, and then your brain interprets the direction of the sound. Unfortunately, this process does not preserve the delays for earphones, because your skull and ears are not inserting the directional delays into the signal.

Binaural recording is a process which includes the delays which give direction in the sound recording process. By placing microphones in the ears of a dummy skull, they same delays which your ears would get by sitting in the space are preserved. Then, when you use earphones, the sound can have direction and create a 3D experience for the listener. Basically, you shift where the ear delays get inserted to the recording process from the listening process.

Our goal

Hardware

Our first step was to transform a pair of earphones into binaural microphones. Binaural microphones are two microphones that can be worn on the ears to record sound from the perspective of a person. We did this by disassembling the ends of the earphones and removing the speakers from them. We then soldered the leads of two Radioshack PC-Mount Condenser Microphone Element mics where the speakers were attached, and reassembled the earphones.
Another simpler way we could have done this would have been to wear the earphones inside out and plug them into the input jack of the computer.
Another simpler way we could have done this would have been to wear the earphones inside out and plug them into the input jack of the computer.
Setup
Next, impulse responses (e.g. claps, gunshots, white noise, chirps) must be created and recorded by the binaural microphones in the space. These impulse responses will characterize the way that the space carries and distributes sound. We chose to record in the Glavin Chapel at Babson College, because it echoes beautifully. We used loud claps as our impulse responses, and recorded them with Audacity coming from each corner of the room as the recorder sat in the center wearing the binaural microphones.

Casey (the recorder) sitting in Glavin Chapel with Jenny (the creeper) behind her.
Software
Finally, once we have recorded these impulse responses, we needed to create a program that would fill the space with the song Bohemian Rhapsody, and create the illusion of it moving around the listener.
The method we used is called convolution. Convolution shifts and scales a signal's frequency spectrum to the impulse response's frequency spectrum. This creates a new modified signal that sounds like the original signal is happening in the location of the impulse response.
The way we approached making the song sound like it was moving continuously through space (rather than staying at the discrete corners where the impulse responses were recorded) was to implement ratios. We would convolve succeeding segments of the song with ratios of two impulses, starting completely from one impulse to the other.
The method we used is called convolution. Convolution shifts and scales a signal's frequency spectrum to the impulse response's frequency spectrum. This creates a new modified signal that sounds like the original signal is happening in the location of the impulse response.
The way we approached making the song sound like it was moving continuously through space (rather than staying at the discrete corners where the impulse responses were recorded) was to implement ratios. We would convolve succeeding segments of the song with ratios of two impulses, starting completely from one impulse to the other.
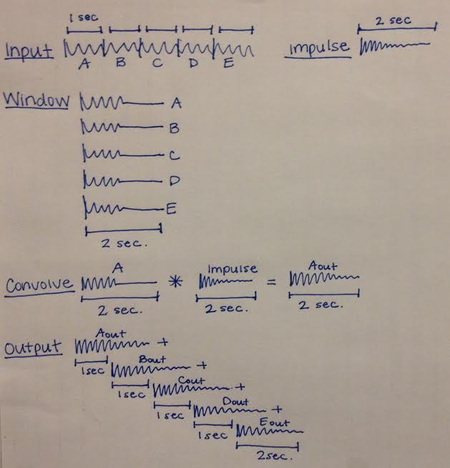 | The diagram to the left illustrates the logic behind our code's segmenting process. We first start with an input signal (in our case, the song Bohemian Rhapsody) and our recorded impulse responses. We kept all of our impulse responses at two seconds, and cut the song into segments of one second each. We then used a boxcar window to add a second of silence to the end of each segment, making them all the same length of the impulse responses. Once we had these two-second segments, we convolved each one with each succeeding ratio of two impulse responses. Instead of convolving these signals in the time domain, we multiplied their spectrums in the frequency domain, which has the same outcome. |
After convolving each segment with its corresponding impulse response, we shifted the output segments by one second and added them back together. The reason we gave them the once-second windows rather than initially segmenting the signal by two seconds was to allow time for each convolved segment to echo into the next segment.
We tested this code first with an input signal of a violin playing, shifting this sound from right to left between two impulse responses.
We tested this code first with an input signal of a violin playing, shifting this sound from right to left between two impulse responses.
Results
First, we convolved two impulse responses with a violin recording. We used a fading linear combination of the two impulse responses to pan the violin recording from one direction to another at a specified rate. Listen to the violin below:
After successfully shifting between two impulses, we decided to take on a greater challenge. We recorded four impulse responses coming from each corner of the chapel, then convolved a clip from the classic song, Bohemian Rhapsody, with linear combinations of the impulse responses. By convolving the song with each impulse response, we can make the song sound like it’s coming from a specific direction. As we shifted the ratios of each impulse response's convolution with the signal, the song seemed to pan around the room. After panning the signal multiple times, our song sounds like this:
Then, we convolved our song with a signal which switched between several impulse responses, like flicking between different LED lights. The song then sounds like this:
When evaluating the success of our signal processing, we made several observations. In theory, the song should float around the listener. The processed song definitely sounded like it was being played in the Glavin Chapel where we collected our impulse responses. Additionally, we heard the sound moving closer and farther. However, we could not distinguish the panning and the jumping in the way that we expected. The panning quality also seems to be stronger before we email or upload the sound file, so we question whether compression may have altered the 3D effect.
The chapel that we recorded the impulse responses in also had a lot of echo. This could have helped with the illusion that the sound was moving, or it may have also distorted the directional sound effect. The echo may minimize the panning because echoes could blur the distinctions between locations.
The chapel that we recorded the impulse responses in also had a lot of echo. This could have helped with the illusion that the sound was moving, or it may have also distorted the directional sound effect. The echo may minimize the panning because echoes could blur the distinctions between locations.
Next Steps
If we were to work further on this project, some aspects in which we would improve would include:
- More spaces: Collect impulse responses in other interesting acoustic spaces (Parcel B, staircase, dining hall) and compare how the processed sounds move and echo differently.
- Better panning: Work to improve the panning feature so that the directions are more recognizable.
- Story-based panning: Start with a video + traditional audio, and have our panning reflect the situations in the video.
- Fake it up: Create virtual impulse responses in iPython to artificially generate binaural sound without the binaural recording process.
Further Reading
What is binaural sound http://en.wikipedia.org/wiki/Binaural_recording
Methods: Hardware http://www.instructables.com/id/how-to-record-binaural-audio-tracks-with-a-homemad/
Methods: Hardware http://www.instructables.com/id/how-to-record-binaural-audio-tracks-with-a-homemad/
